How to Understand On Premises Proprietary Servers and Server Vendors
Executive Summary
- Proprietary on-premises servers are the most popular category of computers that serve other computers.
- This article covers how proprietary on-premises servers work.

Introduction
The largest server computer hardware category is on-premises proprietary servers, the types sold by HPE, Lenovo, and Dell. This is the server type that rose to eclipse mainframes and midrange computers.

The most common server used in data centers is a server blade. A server blade, as with other servers, is a “souped-up” personal computer. The power of servers comes from being connected to many servers through network cabling and then using software rather than performing specialized functions. However, they cannot match workloads to their hardware without extensive virtualization, which then also consumes a high percentage of the server’s capacity, which is the so-called “VM bloat.” Virtual machines themselves require their effort to optimize. When put in place, they follow a “client-server” model just as the mainframe. The most significant vendors in the proprietary server space are HPE, Dell, Lenovo, and Cisco.
The Commodification of the On Proprietary Premises Server Space
The most substantial growth in this market is coming from the established countries and Chinese manufacturers like Inspur, Huawei, and Super Micro. It appears that the US-headquartered proprietary server brands like HPE and Dell will continue to lose market share in the coming years. That is, these companies are being “disintermediated” (as they don’t do any of their manufacturing) with the business going to where the manufacturing is located…. China.
In fact, in our view, a good deal of the market share that HPE, Dell, Lenovo, and Cisco have is because of previous purchases, sales teams, established relationships with buyers, and less because they offer a differentiated product. Many IT departments make their hardware purchase decisions as they make their software purchase decisions, just from what they are accustomed to buying and who they are accustomed to buying from.

The most significant change in hardware purchased will take effect when the current IT managers in companies retire and are replaced by IT managers with more first-hand experience with the cloud and buying from the non-standard hardware vendors with established relationships. It will have less to do with “minds changing” and more to do with management turnover.
Engineered Servers
Of the significant proprietary server vendors, HPE offers the most designed or engineered servers, but they are doing the most poorly of the primary server vendors. The server market is moving towards commoditization and where the design work is performed outside of the server vendors. For this reason, it isn’t easy to project a rosy future for the US-based (headquartered as they make nothing in the US) server companies. It appears that they thought they would be able to get out of the manufacturing business without anyone realizing that they don’t make anything anymore and live a life as hardware intermediaries. The following is a concise explanation of the position faced by HPE from SeekingAlpha.
“In sum, we don’t see a bright future for HPE, primarily because of workload migration to the public cloud, but also because of the hyper-scale and service provider customer segments, which are increasingly unwilling to do business with HPE.(emphasis added) The migration of workloads to public cloud service providers will likely deter companies from increasing investment in on-premises data centers, which means that less infrastructure supplied by HPE will hit the market.
HPE is still a leader in servers, but we still expect cutthroat competition here. The company lacks the size and scale of industry leaders such as Cisco in networking and EMC in enterprise storage. Finally, the revenue growth trend from the last couple of quarters is likely a sign of continued bleeding that won’t stop any time soon. We expect HPE to continue to shrink in the future, and don’t see a business that will start growing any time soon.”

On-premises servers come in different configurations. They are seen here as individual items. They are installed in racks unless the server is a tower.
On-premises servers can be purchased off of Amazon-like consumer computers; used on-premises servers can be bought off of eBay.
The Proposal of On-Premises Servers
On-premises servers came to take over most computing workload in corporate and government environments under the premise that they were far more cost-effective, particularly concerning the initial purchase price than either mainframes or midrange computers. Moreover, while there is no question about the lower acquisition cost of proprietary on-premises servers, after several decades of experience, there are many questions about the validity of the original premise of the overall maintenance costs of on-premises servers.
The Problematic Efficiency of On-Premises Servers
On-premises servers require a significant scale to provide their initial promised efficiency. On average, 80% of on-premises environments are over-provisioned with servers and related hardware. And this realization, in part, has led many startups to avoid on-premises servers entirely and instead of following a 100% cloud strategy. Many startups write about the benefits of not worrying about maintaining on-premises services, allowing them to concentrate on their core business.

On-premises managed servers are less than 50% as utilized as those operated by AWS and Google Cloud.
Large Companies Economies of Scale with Servers
Large companies find on-premises servers more appealing as with their size. They can attain more scale economies that make on-premises servers more feasible. However, the low average utilization of servers is a problem even at large companies and government entities. And the research is detailed that unless a huge number of servers are managed, on-premises servers suffer from significant inefficiencies. For instance, according to the Anthesis Group, roughly 30% of on-premises servers are “comatose.” This is explained in the following quotation.
“The core findings are based on a sample of anonymized data and revealed that 30 percent of the physical servers were “comatose.” In this instance, comatose or zombie servers are those that have not delivered information or computing services in six months or more.
These findings imply that there are about 10 million comatose servers worldwide – including standalone servers and host servers in virtual environments. The findings support previous research performed by the Uptime Institute, which also found that around 30 percent of servers are unused. The 10 million estimated comatose servers translate into at least $30 billion in data center capital sitting idle globally (assuming an average server cost of $3,000, while ignoring infrastructure capital costs as well as operating costs).”
Think through how often you read this or this topic is a focus in IT media. Unless this is your area of specialization, the likely answer is very little. The Uptime Institute provides the following reasons for this inefficiency.
“Data centers often have excess server capacity because identifying unused or over-provisioned hardware with certainty is difficult with conventional tools. Managing resources simply by measuring CPU and memory usage alone isn’t enough to ensure that a particular server is comatose. Data center operators also need to look at upstream traffic or user access information per server from central IT management, virtualization and workload distribution systems. This approach identifies IT resources not doing any useful work so they can be decommissioned without adding risk to the business.”
Estimating Comatose Servers
This estimation of comatose servers is just the extreme side of the continuum of server waste. But it is real, and it begs the question as to why these comatose servers are left plugged in. That is, servers that do absolutely nothing but consume power and incur maintenance costs. The far more common form of server waste is servers with deficient utilization levels, which is commonly estimated that the average server is somewhere between 5% to 15% utilized.
When compared against the other major computer hardware modalities (cloud, mainframe, midrange, specialized appliances), on-premises servers are the most wasteful of any of them by a wide margin.
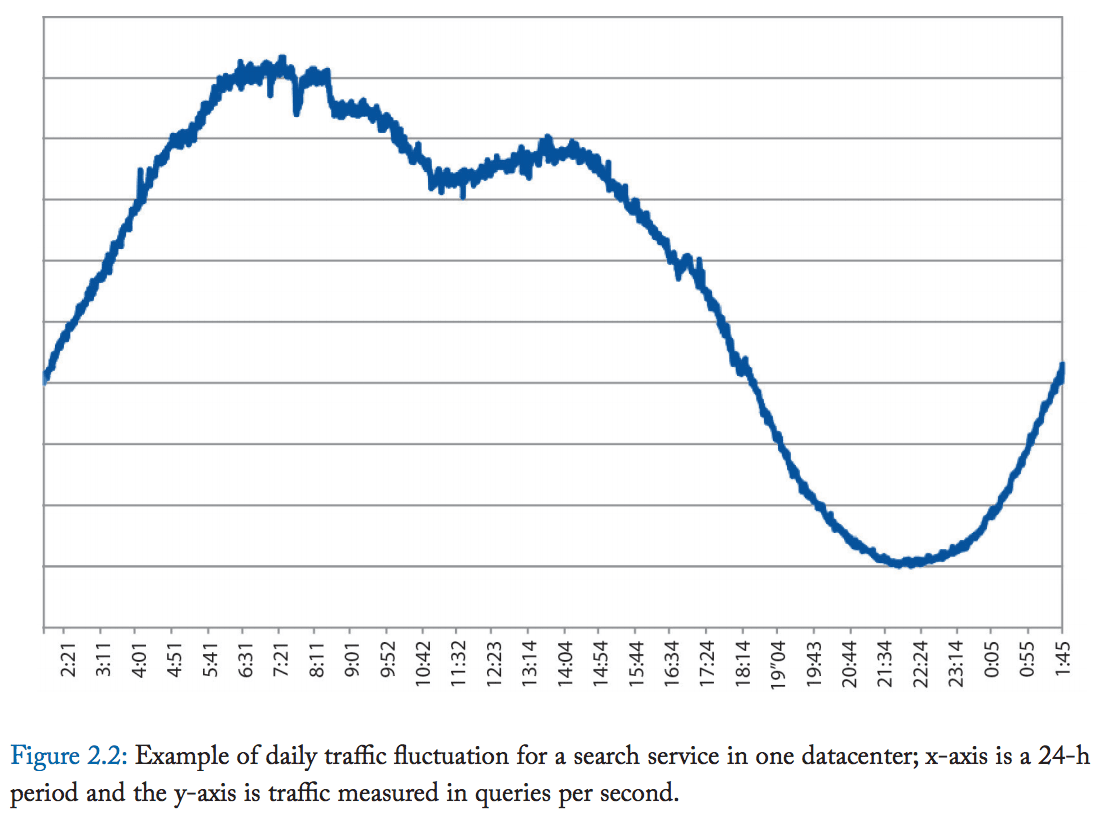
Server load fluctuations are a constant factor that reduces the utilization of different hardware modalities. The more fluctuations exist, the lower the average utilization will be, all other things being equal.
Fact Checking Projections
This is the problem with an entirely commercially driven environment. There is little incentive to go back and check how accurate the projections were versus what occurred. HPE and Dell do not advertise that customers should expect to receive an average utilization of 5% to 15% from their server purchases (and the utilization depends upon what exactly is measured, CPU or memory or the IO bandwidth, with memory and IO bandwidth normally being far more utilized than the CPU). HPE and Dell and other vendors have a long-term sales strategy to oversell their hardware to their customers as a matter of routine. A common rule of thumb used by salespeople at HPE (taken from a previous HPE employee) is to increase the customer’s current hardware configuration by 50% during a hardware upgrade. That is, sales do not account for current utilization but rather apply assumed growth for each upgrade. And amazingly, this goes unchallenged by many HPE customers (and we will assume Cisco, Dell, and Lenovo customers as well).
So while the low utilization of on-premises servers is a bad thing for on-premises server customers, it is a perfect thing for on-premises server vendors. Ultimately the major server vendors would like to push utilization down below the 5% level (2% perhaps the target?), as this is profit-maximizing. The more redundant hardware, the higher the overall sales. With declining sales on the horizon, the on-premises proprietary server vendors will be particularly motivated to increase their customers’ hardware redundancy. It should be noted that this problem was supposed to be solved by virtualization. However, the utilization of on-premises servers, even with virtualization, continues to be meager many years after IT departments have had ample time to master virtualization.
Conclusion
- Introduced with great fanfare under the client-server model, on-premises servers became the least efficient computer hardware modalities since computers were first introduced.
- It goes undiscussed how customers have been oversold servers by the on-premises vendors and how little control IT departments have exercised over their server farms. We have researched this topic and found a comparatively small amount of coverage of this area. This has resulted in IT departments having too much server complexity and too many servers. The best illustration of this is the fact that most IT departments do not monitor their servers well enough to know when comatose servers should be unplugged from the wall. Part of this may also be because a plugged-in server can be claimed to be working, while a mothballed server must be written off. Therefore, the IT department does know about their comatose servers but would prefer that others within their organization do not know.
- The proprietary on-premises server vendors have created an environment that is ripe for disruption. This is because the proprietary on-premises server sells far too many servers to their customers and does little to help their customers better manage their server investments. Overprovisioning is far more difficult to do with the cloud service providers, and the cloud service providers are far more sophisticated buyers and managers of their server investments. It is far easier to see services that are not being utilized and to shut them down. With servers that are purchased, the writing off of such assets has political consequences.
This leads into the next article, where we cover how the industry moved from mainframes and midrange computers to on-premises proprietary servers.