How to Understand The Journey from Mainframe to Client Server to the Cloud
Executive Summary
- The current proprietary on-premise server environment grew out of mainframes.
- This article tells this story.

We are at a historically important crossroads in the history of IT. This is because IT is going back to its origins in several important ways as IT began its life in the late 1950s with mainframes and a highly centralized computing model. In this article, we will go back in time. In fact, the first portion of the article may seem not directly related to the topic of cloud services. However, as the article concludes, trust that it will all be tied together.
Our References for This Article
If you want to see our references for this article and other related Brightwork articles, see this link.
********
Note: In this article will frequently refer to IBM’s mainframe names and IBM’s mainframe technology. This is not should not be viewed as an endorsement for IBM. Neither IBM nor any other mainframe or other vendor or entity contributed to or had any involvement in the book. We had no contact with any IBM resource before the book’s publication. Neither are we fans of IBM as a company, nor should any of our references to IBM be viewed as an endorsement of their business practices. IBM is only used as a reference due to IBM’s influence, history, and market share in the mainframe market. Due to these factors, they have the easiest and most consistent information published (both by IBM and by independent sources)
********
Let us review the origins and pre-origins of the mainframe model.

This is the Teletype Model 19 introduced in 1940 before mainframes. The first terminals were text input and text output and based upon this machine design. The input was typed, and the output was typed on a computer-controlled typewriter called a teleprinter that worked off a Morse code derivative called Baudot code.
The teleprinters system connected over the phone lines for sending text-based messages was called the “telex” network, which had its origins in Germany in 1926 and could produce 66 words in a minute (50 baud). The telex system was in place before computers arrived on the scene.
This communication system was international and could send messages to multiple receiving locations by sending to a list, with entities like the Associated Press sending out stories “over the wire” for a local publication. The Associated Press was a way of distributing news and pushed forward the standardization of telex networks. The news was distributed continuously to the same points in the telex network. The prevalent Teletype machines were made by Teletype Corporation, which was part of ATT’s Western Electric, a dominant entity in the telex industry. The following table illustrates the meaning of different binaries that were sent over the telex network.
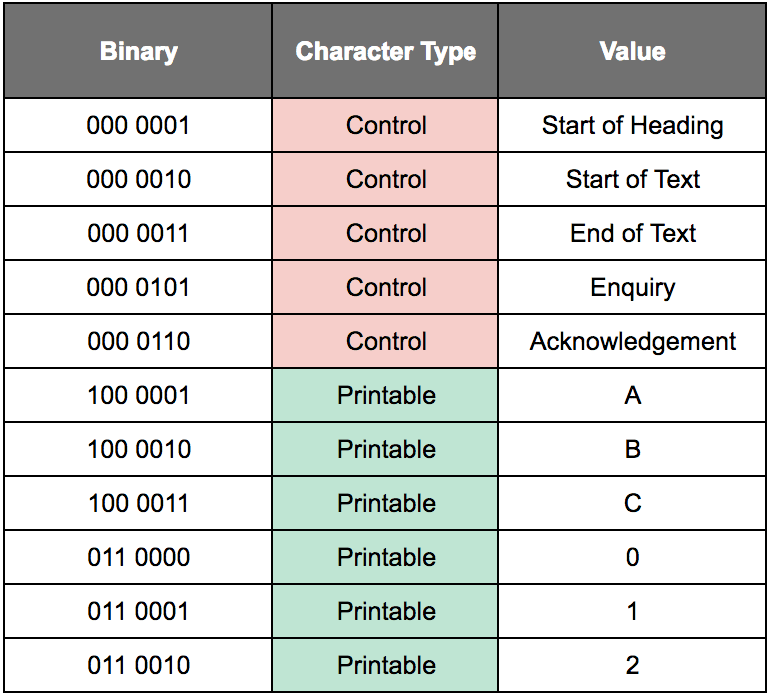
This is a simplified and truncated table that provides some examples of ASCII. An all-inclusive table would be far larger, but this is large enough to give a general idea of how the code functioned. ASCII has both control characters and printable characters. ASCII was proposed in 1961 to allow computers to communicate more easily, and ASCII replaced Baudot code.
After the codes and lines were standardized, a significant jump in communications connected computer terminals to this system. These computer terminals replaced many of the Teletype machines.

This is the CTC Datapoint 3300 Video Terminal, the first commercially successful “dumb terminal” introduced in 1969. It could read punch cards at a speed of 600 per minute (with the Card Reader attachment), and it came with a Magnetic Tape Unit that provided a permanent record of all transactions. The tape unit could reproduce the transactions and resend them at any time. It could also connect over the telephone network. The Datapoint 3300 was also known as the DEC VT06 and the HP 2600A. A local terminal like the 3300 was more of a “window” that allowed one to access processing and data on a centralized mainframe.

In 1971, the CTC Datapoint 2200 was introduced, which is no longer a dumb terminal but has internal processing capabilities. It was referred to as an “intelligent terminal,” and therefore, is a computer but without the modern innards of a central processing unit. Although it was usually still connected to the mainframe, some customers began using it as a stand-alone computer, which was CTC’s actual intent for the CTC Datapoint 2200. Curiously, while CTC intended this in the design, CTC did not market it as such. This is because it was thought to have concerned investors. This was five years before the Apple 1 was introduced, and the idea of presenting a concept as radical as a stand-alone computer was considered too for the time. Investors wanted to invest in terminal companies, which is not something that would make people think of competition with IBM if the term “computer” were used.
Gaining Clarity on the Client-Server Versus Mainframe Debate, Beginning with Terminology
A client-server model is where the client makes requests on a server. This model applies to any terminal connection to a mainframe, which makes one question why the term “client-server architecture” was used to describe the use of computers connected to servers.
- A client-server model is followed if a terminal is connected to a mainframe.
- If a computer is connected to a “server,” a client-server model is followed.
- A client-server model is followed if a computer is connected to Wikipedia’s web server.
Therefore, using the terminology of “client-server” to contrast against the mainframe model can be seen as inaccurate. The distinction is that what we now call “servers,” which in the beginning were larger, more powerful computers, were used to serve requests to smaller computers, terminals, or eventually personal computers. A critical distinction is that while mainframes differ significantly in their design from personal computers, servers do not.
Using the term server to describe such a computer is not helpful in our discussion because a mainframe is also a server. To clarify this, let us review how different computer hardware modalities through computing history line up with the client-server framework and where processing is performed.
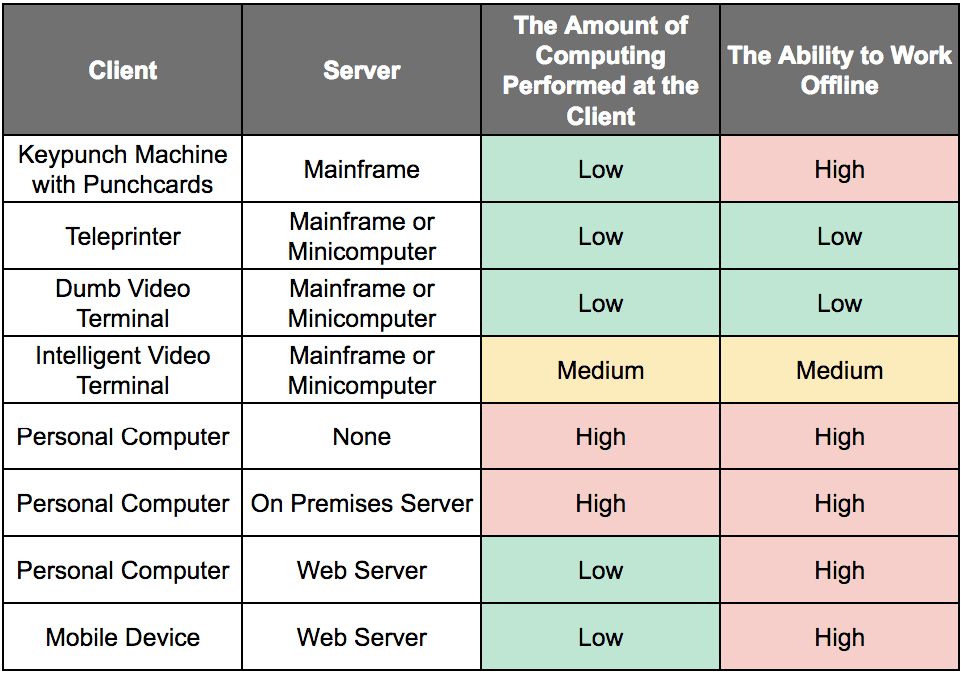
In the table above, two columns have been added to the significant client-server interactions since computing began. Combining the personal computer with an on-premises server marks the high point of the processing being performed. This is both on the client and the server.
As the table above illustrates, computing has nearly always followed a client-server model. The only thing that has changed is the devices used over time. The only people not performing client-server computing have historically only performed personal computing on a personal computer that is not connected to anything else. Everything else is a client-server design. Therefore referring to the combination of a computer with an on-premises server as “client-server” does not make much sense.
A server is a description of the relationship between two computers. It is not a description of a hardware design. A modern blade server uses replication of a standard configuration (replication as in many copies of the same shape). Therefore a modern server could be called an “RSC” computer.
The Great Leap Forward with Client-Server?
With the client-server model and personal computers, the industry moved to a distributed computing model. This was proposed as a great leap forward, but the benefits of client-server now appear significantly overstated. Furthermore, the move to client-server came with some unintended consequences, making the projections about them even less desirable when they were first introduced.
- First, IT departments had to grow to maintain the significant growth in personal computers and servers. This was aggravated by the rise in popularity of the Windows operating system, which was selected as their end-user operating system for compatibility reasons. Windows is both a computer resource vacuum cleaner and a high-maintenance item. Those who own their own Windows machines can attest to this fact.
- Secondly, the skills also changed from supporting primarily mainframes to supporting high overhead servers and large numbers of Windows PCs.
Moreover, client-server and even cloud are not like-for-like replacements for mainframes, as the following quotation attests.
“Can a mainframe deliver the agility, efficiency, and quality that cloud computing provides? One beefy mainframe can be more useful than a fleet of commodity boxes, but only for certain types of work. No one is going to buy a new IBM z10 for small workloads—that would be like buying a big truck for the school run—but on a large scale it can be a better choice. Despite the high cost, mainframe use may be cheaper than commodity hardware use for enterprise-scale workloads.”
High Processing Capabilities on Both Ends
Today, under the client-server model, computers have moved towards powerful local processing, but they are increasingly spending their time accessing remote servers. The following quotation highlights this exact fact.
“If past is truly prologue, then it shouldn’t come as a surprise to anyone who has studied the history of data infrastructure that virtualization, advanced cloud architectures and open, distributed computing models are starting to look a lot like the mainframe of old—albeit on a larger scale. Everywhere you look, in fact, people are talking about pooled resources, higher utilization rates, integrated systems and a rash of other mainframe-like features intended to help the enterprise cope with the rising tide of digital information. Put another way: If the network is the new PC, then the data center is the new “mainframe.”
Proprietary Mainframe-Based Network Architectures Versus the Internet
And what happened in the intervening years between the origins of client-server and cloud? The Internet, of course. IBM created a proprietary network architecture to connect mainframes called SNA or Systems Network Architecture.
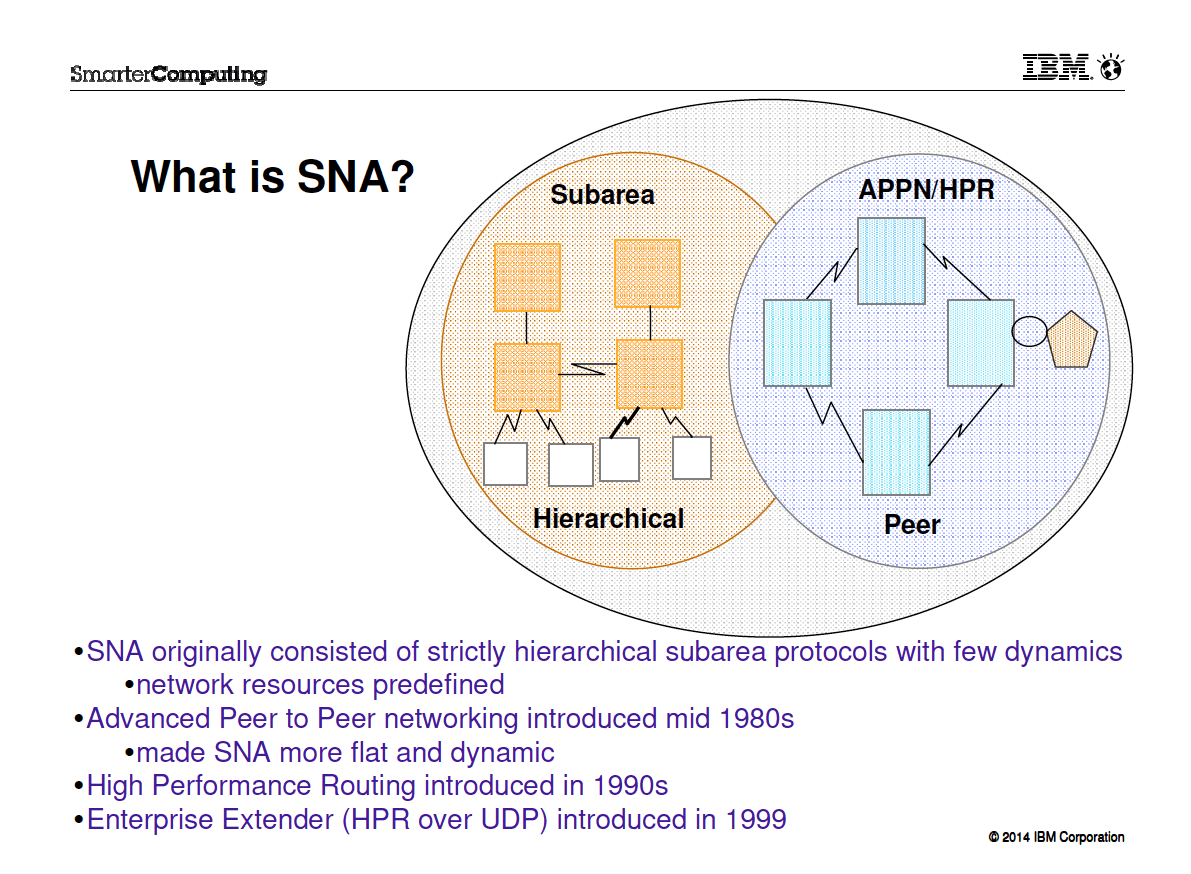
The objective of SNA was to reduce the cost of connecting terminals and the mainframe and peripherals. It is also to improve the ability to manage large networks.
Reading through IBM’s Networking on z/OS documentation with an initial publication date of 2006 and updated in 2010, it is interesting to find this quotation.
“IBM’s current mainframe technology provides significantly large servers with a distinctive strength of handling a high volume of transactions and input/output operations in parallel. The mainframe is capable of serving a large number of network nodes geographically dispersed across the world while simultaneously handling a high volume of input and output operations to disk storage, printers, and other attached computers.
SNA was developed by IBM for the business community. SNA provided industry with a technology that permitted unparalleled business opportunities. What
TCP/IP and the Internet were to the public in the 1990s, SNA was to large enterprises in the 1980s.TCP/IP was widely embraced when the Internet came of age because it permitted access to remote data and processing for a relatively small cost. TCP/IP and the Internet resulted in a proliferation of small computers and communications equipment for chat, e-mail, conducting business, and downloading and uploading data.”
It seems as if IBM corroborates our conclusion that SNA was essentially an early (although private and far more limited use) Internet. While SNA used the SNA network protocol, TCP/IP becomes the network protocol of the Internet.
Proprietary Versus Open Internet
Competitors created their proprietary network architectures (DSA for Honeywell Bull, DCA for Unisys, IPA for DEC). At the same time, mainframes were internal to the company (like on-premises servers today) and operated over proprietary networks. For example, bank ATMs have been commonly supported by mainframes, with communication going over a private network and ATMs being the “terminals.”
The Internet allowed remote access to cloud computers. This allowed access over a universal network and, therefore, access to worldwide computing assets. Not at the beginning of the Internet, but later, static websites eventually gave way to websites that allowed input, ultimately giving away to SaaS applications. Using SaaS applications eventually cleared the way down the stack so that cloud service providers like AWS and Google Cloud rented out infrastructure.
Interestingly, none of these developments are part of the original design concept of the Internet.
Migrating the Mainframe into the Cloud
A natural topic is whether it makes sense to port mainframe systems to the cloud. In many cases, this is not the right approach, as the mainframe a natural fit for on-premises environments. And mainframes do not require or benefit very much from scale economies. But as mainframes purchased years ago age into obsolescence, the cloud increasingly competes with new ones. AWS has the following diagram, which covers this topic specifically.
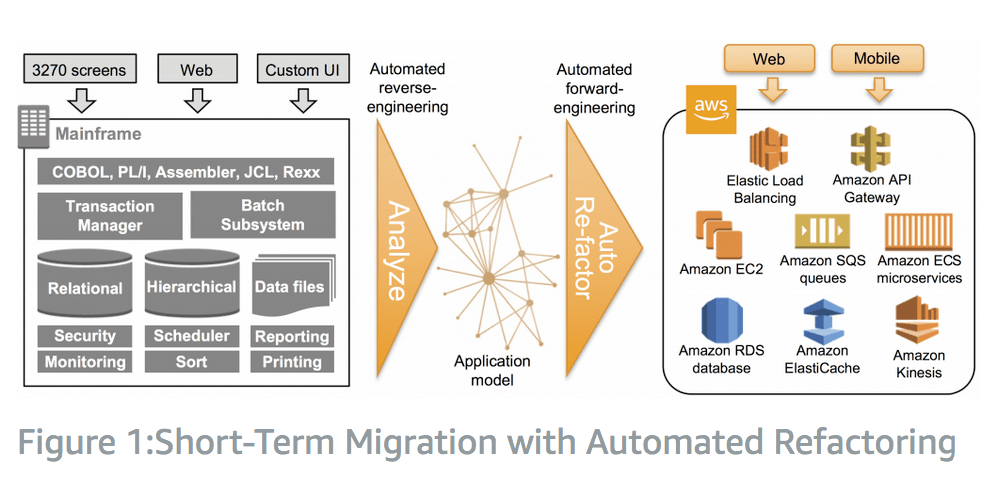
AWS provides the example of a Department of Defense system that was migrated to AWS. This is the most dramatic type of migration – which AWS calls a refactor.
“As an example, a United States Department of Defense customer automatically refactored a complete mainframe COBOL and C-logistics system (millions of lines of code) to Java on AWS, removing the legacy code technical debt.”
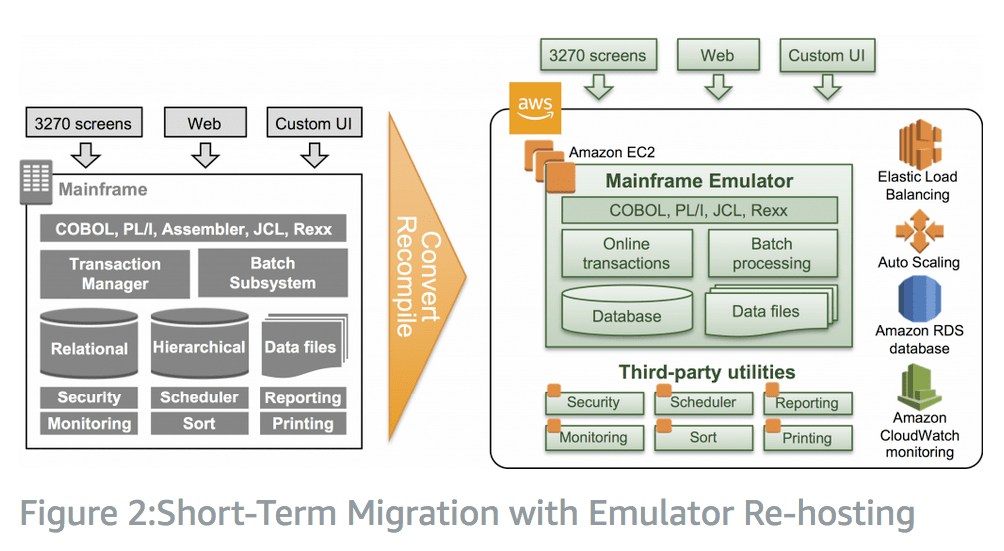
The second option is far less drastic and reproduces the components of the mainframe with a mainframe emulator. AWS observes that this change occurs while keeping the same “interfaces, look and feel of the application.”
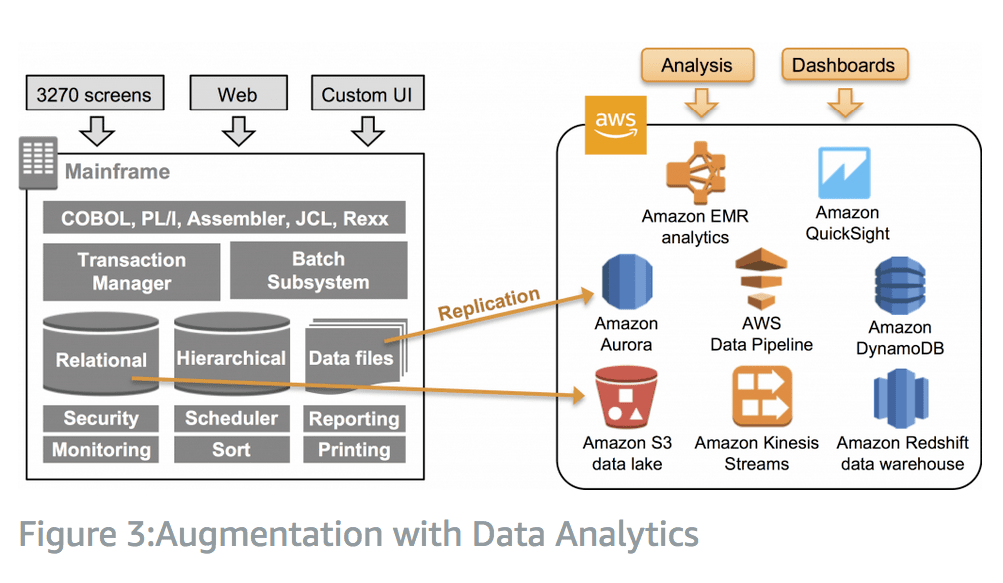
A third option is the least drastic, where the mainframe is kept in place, but data is replicated to databases and storage in AWS, where analytics can be run using cloud services. All of the workloads stay on the mainframe.
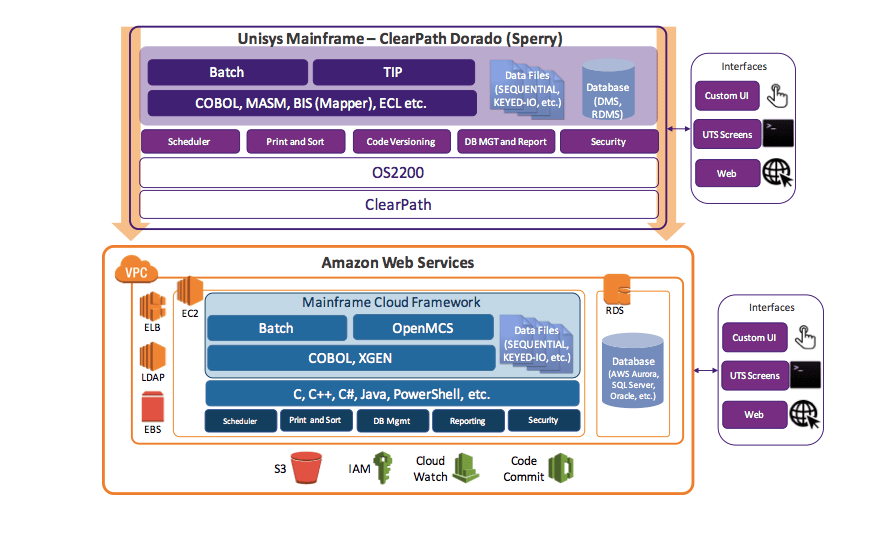
This is a graphic explaining how to migrate Unisys to AWS. However, the assumption is that AWS is a good choice for processing mainframe workloads.
What is undiscussed on the many consulting companies and vendors that have marketed how either servers or cloud should replace “legacy” mainframes is that many migrations from mainframes have failed. One thing to remember is that consulting makes money on implementing systems and change. Therefore the more change, the higher their billable hours. As such, they are unreliable sources on what should and should not be changed. Furthermore, if we look at the results of these recommendations, the outcomes are not encouraging.